
 MENU
MENU 
Research Goals
Our goals are to advance speech-centered machine learning for human behavior detection. We focus on three main areas: 1) emotion recognition, 2) mental health modeling, and 3) assistive technology.
The research in this page is broken into focus areas. Please click on the accordion boxes in each section to see a subset of relevant papers, published since 2016.
Emotion Recognition
General Purpose Emotion Recognition
Emotion is often subtle and ambiguous. Yet, it is central to our communication and provides critical information about our wellness. Consequently, there has been extensive work asking how emotion can be automatically detected from speech samples. This work has focused on classifier design (more recently, network architectures) and feature engineering (or feature learning).
- Classifier Design
Emotion recognition is unlike many other machine learning domains. In emotion, the ground truth is subjective and variable based on context. As a result, it is critical that emotion recognition itself be approached with a keen focus on not “just” predicting the correct labels for a given example (acknowledging that this, in and of itself, is a difficult task), but do so in a manner that is in line with what we understand about the processes through which humans themselves recognize emotion. Our work in this area is fundamentally human-centered and perception-driven. For example, our recent work has proposed new perception-centered deep metric learning approaches [AAAI 2019]. We created a loss-function that encourages the network to learn high-dimensional representations for emotion in which distances between samples correspond to the similarities (or differences) between emotion examples. The use of this loss function, based on the family of f-divergence measures, results in emotion representations that are more effective for extracting emotion labels and less at risk for overtraining. We continually reflect on the fact that emotion perception is influenced by context (we explore the effects of context on emotion annotations and it’s influence on classifier performance in this paper, described in the robust and generalizable emotion recognition section, below) and interpersonal differences, among other factors [ICASSP 2019]. As a result, it is likely not ideal to recognize emotion as a single label. Instead, we advocate for recognizing emotion as a distribution over annotators [ICMI 2017]. The benefit of this approach is that it allows us to leverage variability and, if needed, still collapse down to a single point estimate. Further, practically, we find that using these types of approaches improves the prediction accuracy for valence (positive vs. negative) and brings a consistent performance improvement over data recorded from natural interactions.
Matthew Perez, Mimansa Jaiswal, Minxue Niu, Cristina Gorrostieta, Matthew Roddy, Kye Taylor, Reza Lotfian, John Kane, Emily Mower Provost. “Mind the Gap: On the Value of Silence Representations to Lexical-Based Speech Emotion Recognition.” Interspeech. Incheon, Korea. September 2022.
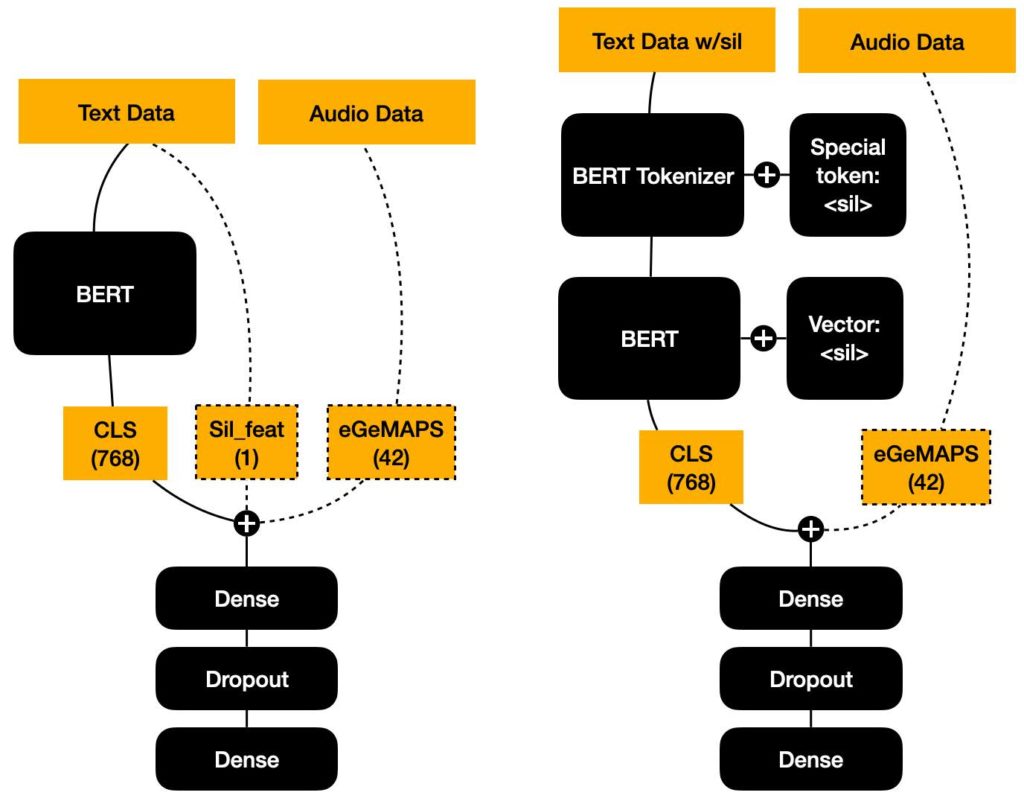
Abstract: Speech timing and non-speech regions (here referred to as “silence”), often play a critical role in the perception of spoken language. Silence represents an important paralinguistic component in communication. For example, some of its functions include conveying emphasis, dramatization, or even sarcasm. In speech emotion recognition (SER), there has been relatively little work on investigating the utility of silence and no work regarding the effect of silence on linguistics. In this work, we present a novel framework which investigates fusing linguistic and silence representations for emotion recognition in naturalistic speech using the MSP-Podcast dataset. We investigate two methods to represent silence in SER models; the first approach uses utterance-level statistics, while the second learns a silence token embedding within a transformer language model. Our results show that modeling silence does improve SER performance and that modeling silence as a token in a transformer language model significantly improves performance on MSP-Podcast achieving a concordance correlation coefficient of .191 and .453 for activation and valence respectively. In addition, we perform analyses on the attention of silence and find that silence emphasizes the attention of its surrounding words.
Biqiao Zhang, Yuqing Kong, Georg Essl, Emily Mower Provost. “f-Similarity Preservation Loss for Soft Labels: A Demonstration on Cross-Corpus Speech Emotion Recognition.” AAAI. Hawaii. January 2019.
Abstract: In this paper, we propose a Deep Metric Learning (DML) approach that supports soft labels. DML seeks to learn representations that encode the similarity between examples through deep neural networks. DML generally presupposes that data can be divided into discrete classes using hard labels. However, some tasks, such as our exemplary domain of speech emotion recognition (SER), work with inherently subjective data, data for which it may not be possible to identify a single hard label. We propose a family of loss functions, f- Similarity Preservation Loss (f-SPL), based on the dual form of f-divergence for DML with soft labels. We show that the minimizer of f-SPL preserves the pairwise label similarities in the learned feature embeddings. We demonstrate the efficacy of the proposed loss function on the task of cross-corpus SER with soft labels. Our approach, which combines f-SPL and classification loss, significantly outperforms a baseline SER system with the same structure but trained with only classification loss in most experiments.We show that the presented techniques are more robust to over-training and can learn an embedding space in which the similarity between examples is meaningful.
Biqiao Zhang, Soheil Khorram, and Emily Mower Provost. “Exploiting Acoustic and Lexical Properties of Phonemes to Recognize Valence from Speech.” International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Brighton, England. May 2019.
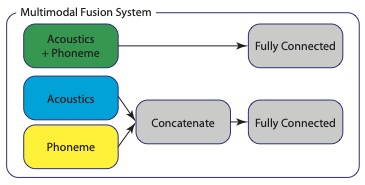
Abstract: Emotions modulate speech acoustics as well as language. The latter influences the sequences of phonemes that are produced, which in turn further modulate the acoustics. Therefore, phonemes impact emotion recognition in two ways: (1) they introduce an additional source of variability in speech signals and (2) they provide information about the emotion expressed in speech content. Previous work in speech emotion recognition has considered (1) or (2), individually. In this paper, we investigate how we can jointly consider both factors to improve the prediction of emotional valence (positive vs. negative), and the relationship between improved prediction and the emotion elicitation process (e.g., fixed script, improvisation, natural interaction). We present a network that exploits both the acoustic and the lexical properties of phonetic information using multi-stage fu- sion. Our results on the IEMOCAP and MSP-Improv datasets show that our approach outperforms systems that either do not consider the influence of phonetic information or that only consider a single aspect of this influence.
Biqiao Zhang, Georg Essl, and Emily Mower Provost. “Predicting the Distribution of Emotion Perception: Capturing Inter-Rater Variability.” International Conference on Multimodal Interaction (ICMI). Glasgow, Scotland, November 2017. [Note: full paper, oral presentation]
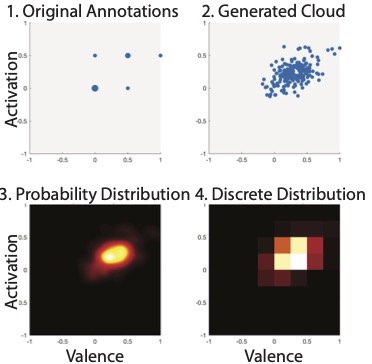
Abstract: Emotion perception is person-dependent and variable. Dimensional characterizations of emotion can capture this variability by describing emotion in terms of its properties (e.g., valence, positive vs. negative, and activation, calm vs. excited). However, in many emotion recognition systems, this variability is often considered “noise” and is attenuated by averaging across raters. Yet, inter-rater variability provides information about the subtlety or clarity of an emotional expression and can be used to describe complex emotions. In this paper, we investigate methods that can effectively capture the variabil- ity across evaluators by predicting emotion perception as a discrete probability distribution in the valence-activation space. We propose: (1) a label processing method that can generate two-dimensional discrete probability distributions of emotion from a limited number of ordinal labels; (2) a new approach that predicts the generated probabilistic distributions using dynamic audio-visual features and Convolutional Neural Networks (CNNs). Our experimental results on the MSP-IMPROV corpus suggest that the proposed approach is more effective than the conventional Support Vector Regressions (SVRs) approach with utterance-level statistical features, and that feature-level fusion of the audio and video modalities outperforms decision-level fusion. The proposed CNN model predominantly improves the prediction accuracy for the valence dimension and brings a consistent performance improvement over data recorded from natural interactions. The results demonstrate the effectiveness of generating emotion distributions from limited number of labels and predicting the distribution using dynamic features and neural networks.
Zakaria Aldeneh, Soheil Khorram, Dimitrios Dimitriadis, Emily Mower Provost. “Pooling Acoustic and Lexical Features for the Prediction of Valence.” International Conference on Multimodal Interaction (ICMI). Glasgow, Scotland, November 2017. [Note: short paper, oral presentation]
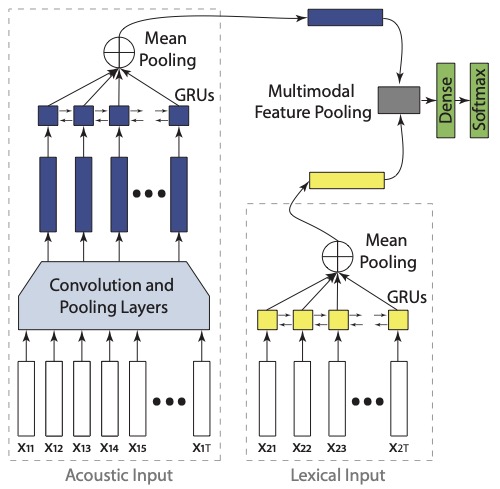
Abstract: In this paper, we present an analysis of different multimodal fusion approaches in the context of deep learning, focusing on pooling intermediate representations learned for the acoustic and lexical modalities. Traditional approaches to multimodal feature pooling include: concatenation, element-wise addition, and element-wise multiplication. We compare these traditional methods to outer-product and compact bilinear pooling approaches, which consider more comprehensive interactions between features from the two modalities. We also study the influence of each modality on the overall performance of a multimodal system. Our experiments on the IEMOCAP dataset suggest that: (1) multimodal methods that combine acoustic and lexical features outperform their unimodal counterparts; (2) the lexical modality is better for predicting va- lence than the acoustic modality; (3) outer-product-based pooling strategies outperform other pooling strategies.
Duc Le, Zakariah Aldeneh, and Emily Mower Provost. “Discretized Continuous Speech Emotion Recognition with Multi-Task Deep Recurrent Neural Network.” Interspeech. Stockholm, Sweden, August 2017.
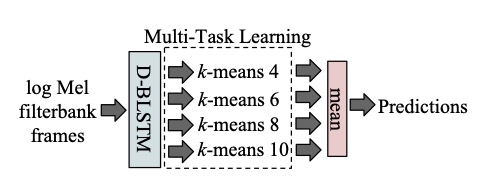
Abstract: Estimating continuous emotional states from speech as a function of time has traditionally been framed as a regression problem. In this paper, we present a novel approach that moves the problem into the classification domain by discretizing the training labels at different resolutions. We employ a multi-task deep bidirectional long-short term memory (BLSTM) recurrent neural network (RNN) trained with cost-sensitive Cross Entropy loss to model these labels jointly. We introduce an emotion decoding algorithm that incorporates long- and short-term temporal properties of the signal to produce more robust time series estimates. We show that our proposed approach achieves competitive audio-only performance on the RECOLA dataset, relative to previously published works as well as other strong regression baselines. This work provides a link between regression and classification, and contributes an alternative approach for continuous emotion recognition.
John Gideon, Soheil Khorram, Zakariah Aldeneh, Dimitrios Dimitriadis, and Emily Mower Provost. “Progressive Neural Networks for Transfer Learning in Emotion Recognition.” Interspeech. Stockholm, Sweden, August 2017.
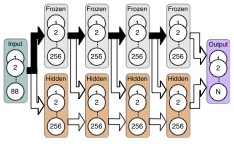
Abstract: Many paralinguistic tasks are closely related and thus represen- tations learned in one domain can be leveraged for another. In this paper, we investigate how knowledge can be transferred between three paralinguistic tasks: speaker, emotion, and gender recognition. Further, we extend this problem to cross-dataset tasks, asking how knowledge captured in one emotion dataset can be transferred to another. We focus on progressive neural networks and compare these networks to the conventional deep learning method of pre-training and fine-tuning. Progressive neural networks provide a way to transfer knowledge and avoid the forgetting effect present when pre-training neural networks on different tasks. Our experiments demonstrate that: (1) emotion recognition can benefit from using representations origi- nally learned for different paralinguistic tasks and (2) transfer learning can effectively leverage additional datasets to improve the performance of emotion recognition systems.
Zakariah Aldeneh and Emily Mower Provost. “Using Regional Saliency for Speech Emotion Recognition.” IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP). New Orleans, Louisiana, USA, March 2017.
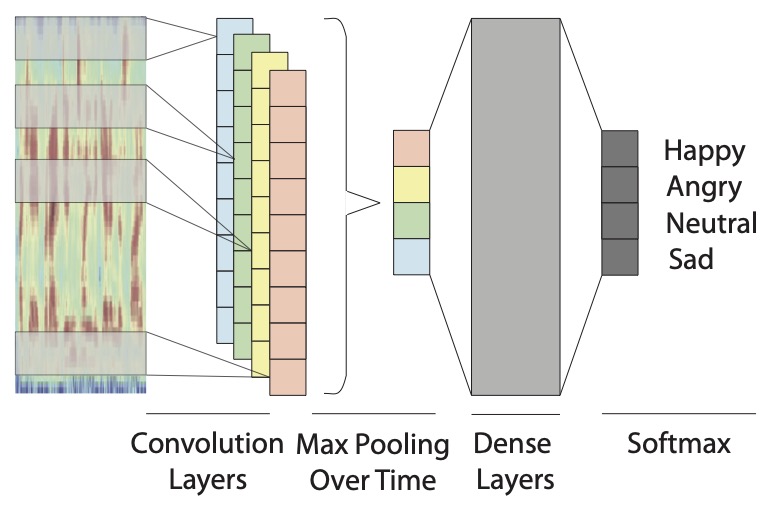
Abstract: In this paper, we show that convolutional neural networks can be directly applied to temporal low-level acoustic features to identify emotionally salient regions without the need for defining or applying utterance-level statistics. We show how a convolutional neural network can be applied to minimally hand-engineered features to obtain competitive results on the IEMOCAP and MSP-IMPROV datasets. In addition, we demonstrate that, despite their common use across most categories of acoustic features, utterance-level statistics may obfuscate emotional information. Our results suggest that convolutional neural networks with Mel Filterbanks (MFBs) can be used as a replacement for classifiers that rely on features obtained from applying utterance-level statistics.
- Feature Engineering and Representation Learning
Features, or short time measurements, are central to being able to accurately recognize emotion. The hope is that the features will capture the variation caused by emotion, while potentially mitigating the variation due to other factors. It is for this reason that a common practice in the field of emotion recognition is to take statistics of low-level speech features (e.g,. Mel Filterbanks) over an entire sentence – obfuscating lexical content while capturing how emotion causes different statistical patterns of the features across the emotion classes, categories, or dimensions. In our recent work, we have asked how we can design new types of features that capture what it means to speak emotionally. In one work, we advocated for the use of features common in speaker verification to capture offset from an individuals typical manner of speaking [IEEE Trans. Affective Computing 2021]. We found that these features were affected by changes in emotion, but not changes in lexical content. In another work, we recast the emotion recognition problem, looking to design features that described the difference between expressive and inexpressive data [NAACL 2021]. If we could use these features to transform inexpressive to expressive speech, we anticipated that the same features could be used in the context of emotion recognition to capture expressive style. We found that the use of such features outperformed other self-supervised techniques in the literature.
Zakaria Aldeneh and Emily Mower Provost. “You’re Not You When You’re Angry: Robust Emotion Features Emerge by Recognizing Speakers,” IEEE Transactions on Affective Computing, vol: To appear, 2021.
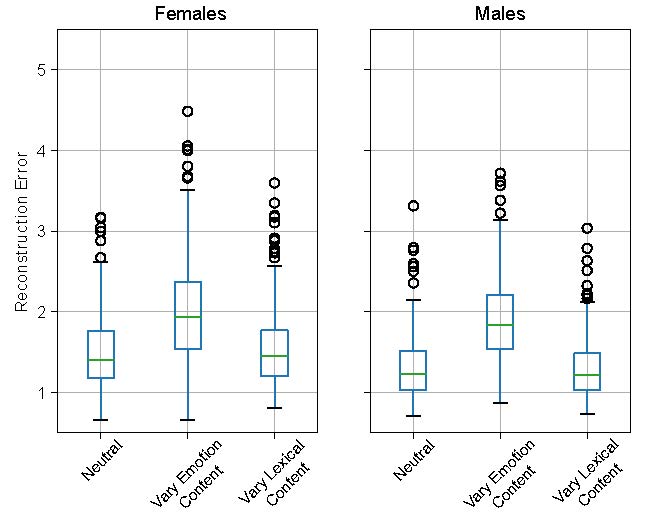
Abstract: The robustness of an acoustic emotion recognition system hinges on first having access to features that represent an acoustic input signal. These representations should abstract extraneous low-level variations present in acoustic signals and only capture speaker characteristics relevant for emotion recognition. Previous research has demonstrated that, in other classification tasks, when large labeled datasets are available, neural networks trained on these data learn to extract robust features from the input signal. However, the datasets used for developing emotion recognition systems remain significantly smaller than those used for developing other speech systems. Thus, acoustic emotion recognition systems remain in need of robust feature representations. In this work, we study the utility of speaker embeddings, representations extracted from a trained speaker recognition network, as robust features for detecting emotions. We first study the relationship between emotions and speaker embeddings and demonstrate how speaker embeddings highlight the differences that exist between neutral speech and emotionally expressive speech. We quantify the modulations that variations in emotional expression incur on speaker embeddings and show how these modulations are greater than those incurred from lexical variations in an utterance. Finally, we demonstrate how speaker embeddings can be used as a replacement for traditional low-level acoustic features for emotion recognition.
Zakaria Aldeneh, Matthew Perez, Emily Mower Provost. “Learning Paralinguistic Features from Audiobooks through Style Voice Conversions.” Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL). Mexico City, Mexico. June 2021.
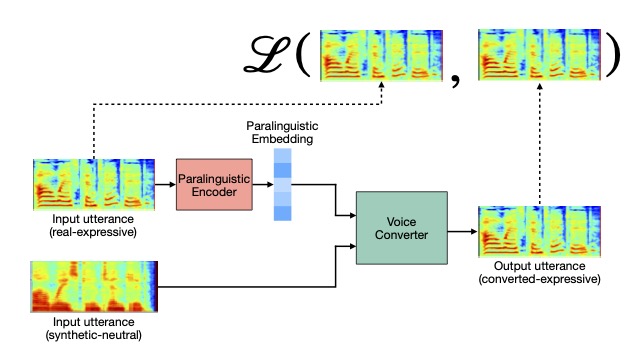
Abstract: Paralinguistics, the non-lexical components of speech, play a crucial role in human-human interaction. Models designed to recognize paralinguistic information, particularly speech emotion and style, are difficult to train because of the limited labeled datasets available. In this work, we present a new framework that enables a neural network to learn to extract par- alinguistic attributes from speech using data that are not annotated for emotion. We as- sess the utility of the learned embeddings on the downstream tasks of emotion recognition and speaking style detection, demonstrating significant improvements over surface acous- tic features as well as over embeddings ex- tracted from other unsupervised approaches. Our work enables future systems to leverage the learned embedding extractor as a separate component capable of highlighting the paralin- guistic components of speech.
Biqiao Zhang, Yuqing Kong, Georg Essl, Emily Mower Provost. “f-Similarity Preservation Loss for Soft Labels: A Demonstration on Cross-Corpus Speech Emotion Recognition.” AAAI. Hawaii. January 2019.
Abstract: In this paper, we propose a Deep Metric Learning (DML) approach that supports soft labels. DML seeks to learn representations that encode the similarity between examples through deep neural networks. DML generally presupposes that data can be divided into discrete classes using hard labels. However, some tasks, such as our exemplary domain of speech emotion recognition (SER), work with inherently subjective data, data for which it may not be possible to identify a single hard label. We propose a family of loss functions, f- Similarity Preservation Loss (f-SPL), based on the dual form of f-divergence for DML with soft labels. We show that the minimizer of f-SPL preserves the pairwise label similarities in the learned feature embeddings. We demonstrate the efficacy of the proposed loss function on the task of cross-corpus SER with soft labels. Our approach, which combines f-SPL and classification loss, significantly outperforms a baseline SER system with the same structure but trained with only classification loss in most experiments.We show that the presented techniques are more robust to over-training and can learn an embedding space in which the similarity between examples is meaningful.
- General Information about Emotion Recognition
Chi-Chun Lee, Theodora Chaspari, Emily Mower Provost and Shrikanth S. Narayanan, “An Engineering View on Emotions and Speech: From Analysis and Predictive Models to Responsible Human-Centered Applications,” in Proceedings of the IEEE, doi: 10.1109/JPROC.2023.3276209.
The substantial growth of Internet-of-Things technology and the ubiquity of smartphone devices has increased the public and industry focus on speech emotion recognition (SER) technologies. Yet, conceptual, technical, and societal challenges restrict the wide adoption of these technologies in various domains, including, healthcare, and education. These challenges are amplified when automated emotion recognition systems are called to function “in-the-wild” due to the inherent complexity and subjectivity of human emotion, the difficulty of obtaining reliable labels at high temporal resolution, and the diverse contextual and environmental factors that confound the expression of emotion in real life. In addition, societal and ethical challenges hamper the wide acceptance and adoption of these technologies, with the public raising questions about user privacy, fairness, and explainability. This article briefly reviews the history of affective speech processing, provides an overview of current state-of-the-art approaches to SER, and discusses algorithmic approaches to render these technologies accessible to all, maximizing their benefits and leading to responsible human-centered computing applications.
Header text
Robust and Generalizable Emotion Recognition
There is also a critical secondary question: how can we create emotion recognition algorithms that are functional in real-world environments? In order to reap the benefits of emotion recognition technologies, we must have systems that are robust and generalizable. Our work focuses on how we can encourage classifiers to learn to recognize emotion in contexts different from the ones in which they have been trained.
- Methods for Noise Robustness and Robustness to Confounders
A common goal in speech emotion recognition is to create classifiers that can be deployed. This requires that the classifiers can accurately function in domains different from the ones in which they were developed. However, this remains an open challenge. New domains are associated with different microphones, different background noise sources, different speakers, etc. Our work in this space has asked how we can create new classifier designs that are specifically designed to be robust in new environments. This has included the design of new architectures that are designed to work in changing acoustic environments and still maintain the temporal context of the emotional data [ACII 2021]. This has also included rethinking the collection of emotional data, moving a way from the standard that the collection should explicitly isolate only emotion. The reality is that our emotions aren’t expressed in isolation, they are generally expressed as something else is also going on in our lives, e.g., when we are stressed. Our recent work has asked how we can collect data that is more emotionally complex, data that has co-mingled stress and emotion [LREC 2020]. We have also asked how we can still robustly recognize emotion, when varying levels of stress are present [ICMI 2019]. We found that we could isolate the variations due to emotion, mitigating the effect of those due to stress, using adversarial techniques. We found that models that mitigated the effects of stress were more accurate in cross-domain settings, compared to those that recognized emotion as a sole task.
James Tavernor, Matthew Perez, Emily Mower Provost. “Episodic Memory For Domain-Adaptable, Robust Speech Emotion Recognition.” Interspeech. Dublin, Ireland. August 2023.
Emotion conveys abundant information that can improve the user experience of various automated systems, in addition to communicating information important for managing well-being. Human speech conveys emotion, but speech emotion recognition models do not perform well in unseen environments. This limits the ubiquitous use of speech emotion recognition models. In this paper, we investigate how a model can be adapted to unseen environments without forgetting previously learned environments. We show that memory-based methods maintain performance on previously seen environments while still being able to adapt to new environments. These methods enable continual training of speech emotion recognition models following deployment while retaining previous knowledge, working towards a more general, adaptable, acoustic model.
Alex Wilf and Emily Mower Provost. “Towards Noise Robust Speech Emotion Recognition Using Dynamic Layer Customization.” Affective Computing and Intelligent Interaction (ACII). Tokyo, Japan. September 2021.
Abstract: Robustness to environmental noise is important to creating automatic speech emotion recognition systems that are deployable in the real world. In this work, we experiment with two paradigms, one where we can anticipate noise sources that will be seen at test time and one where we cannot. In our first experiment, we assume that we have advance knowledge of the noise conditions that will be seen at test time. We show that we can use this knowledge to create “expert” feature encoders for each noise condition. If the noise condition is unchanging, data can be routed to a single encoder to improve robustness. However, if the noise source is variant, this paradigm is too restrictive. In- stead, we introduce a new approach, dynamic layer customization (DLC), that allows the data to be dynamically routed to noise- matched encoders and then recombined. Critically, this process maintains temporal order, enabling extensions for multimodal models that generally benefit from long-term context. In our second experiment, we investigaate whether partial knowledge of noise seen at test time can still be used to train systems that generalize well to unseen noise conditions using state-of-the- art domain adaptation algorithms. We find that DLC enables performance increases in both cases, highlighting the utility of mixture-of-expert approaches, domain adaptation methods and DLC to noise robust automatic speech emotion recognition.
Mimansa Jaiswal, Christian-Paul Bara, Yuanhang Luo, Mihai Burzo, Rada Mihalcea, and Emily Mower Provost, MuSE: a Multimodal Dataset of Stressed Emotion.” Language Resources and Evaluation Conference (LREC) . Marseille, France. May 2020.
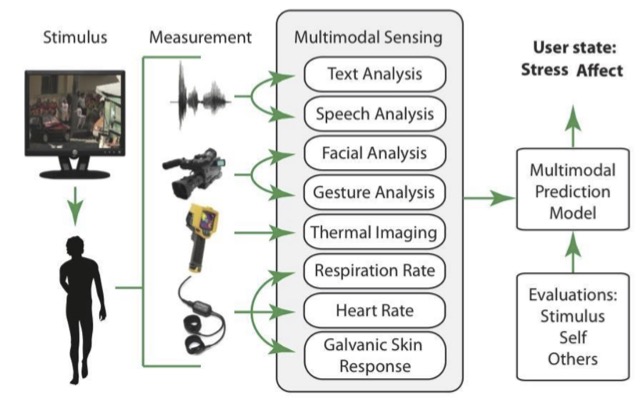
Abstract: Endowing automated agents with the ability to provide support, entertainment and interaction with human beings requires sensing of the users’ affective state. These affective states are impacted by a combination of emotion inducers, current psychological state, and various contextual factors. Although emotion classification in both singular and dyadic settings is an established area, the effects of these additional factors on the production and perception of emotion is understudied. This paper presents a dataset, Multimodal Stressed Emotion (MuSE), to study the multimodal interplay between the presence of stress and expressions of affect. We describe the data collection protocol, the possible areas of use, and the annotations for the emotional content of the recordings. The paper also presents several baselines to measure the performance of multimodal features for emotion and stress classification.
Mimansa Jaiswal, Zakaria Aldeneh, Emily Mower Provost, “Using Adversarial Training to Investigate the Effect of Confounders on Multimodal Emotion Classification.” International Conference on Multimodal Interaction (ICMI). Suzhou, Jiangsu, China. October 2019.
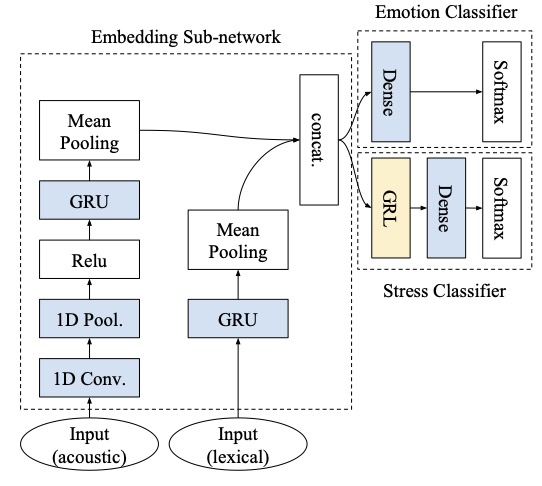
Abstract: Endowing automated agents with the ability to provide support, entertainment and interaction with human beings requires sensing of the users’ affective state. These affective states are impacted by a combination of emotion inducers, current psychological state, and various contextual factors. Although emotion classification in both singular and dyadic settings is an established area, the effects of these additional factors on the production and perception of emotion is understudied. This paper presents a dataset, Multimodal Stressed Emotion (MuSE), to study the multimodal interplay between the presence of stress and expressions of affect. We describe the data collection protocol, the possible areas of use, and the annotations for the emotional content of the recordings. The paper also presents several baselines to measure the performance of multimodal features for emotion and stress classification.
Mimansa Jaiswal, Zakaria Aldeneh, Cristian-Paul Bara, Yuanhang Luo, Mihai Burzo, Rada Mihalcea, Emily Mower Provost. “MuSE-ing on the impact of utterance ordering on crowdsourced emotion annotations.” International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Brighton, England. May 2019.
Abstract: Emotion recognition algorithms rely on data annotated with high quality labels. However, emotion expression and perception are in- herently subjective. There is generally not a single annotation that can be unambiguously declared “correct”. As a result, annotations are colored by the manner in which they were collected. In this paper, we conduct crowdsourcing experiments to investigate this impact on both the annotations themselves and on the performance of these al- gorithms. We focus on one critical question: the effect of context. We present a new emotion dataset, Multimodal Stressed Emotion (MuSE), and annotate the dataset using two conditions: randomized, in which annotators are presented with clips in random order, and contextualized, in which annotators are presented with clips in order. We find that contextual labeling schemes result in annotations that are more similar to a speaker’s own self-reported labels and that la- bels generated from randomized schemes are most easily predictable by automated systems.
- Generalizability
When our environment changes, the acoustics of our emotion expressions change as well. However, as humans, we know that this does not mean that in a new environment we lose the ability to recognize the emotion expressions of others. Yet, this is often the case for our classifiers. Our goal is to create methods that find what is common in between emotion expressed in different environments and to use these commonalities to recognize emotion in a more generalizable manner. In one paper, we advocated for the creation of new “meet in the middle” approaches that learn to identify commonalities between emotion expressions from different datasets [IEEE Transactions on Affective Computing 2019]. We referred to this method as Adversarial Discriminative Domain Generalization (ADDoG). It was inspired by domain generalization techniques, but reflected on a common failing in these approaches applied to emotion recognition: instability and mode collapse. We created a new technique that iteratively moved representations learned for each dataset closer to one another, improving cross-dataset generalization and significantly improving cross-dataset performance.
John Gideon, Melvin McInnis, Emily Mower Provost. “Improving Cross-Corpus Speech Emotion Recognition with Adversarial Discriminative Domain Generalization (ADDoG),” IEEE Transactions on Affective Computing, vol:12, issue:4, Oct.-Dec., 2019. [Note: selected as one of five papers for the Best of IEEE Transactions on Affective Computing 2021 Paper Collection]
Abstract: Automatic speech emotion recognition provides computers with critical context to enable user understanding. While methods trained and tested within the same dataset have been shown successful, they often fail when applied to unseen datasets. To address this, recent work has focused on adversarial methods to find more generalized representations of emotional speech. However, many of these methods have issues converging, and only involve datasets collected in laboratory conditions. In this paper, we introduce Adversarial Discriminative Domain Generalization (ADDoG), which follows an easier to train “meet in the middle” approach. The model iteratively moves representations learned for each dataset closer to one another, improving cross-dataset generalization. We also introduce Multiclass ADDoG, or MADDoG, which is able to extend the proposed method to more than two datasets, simultaneously. Our results show consistent convergence for the introduced methods, with significantly improved results when not using labels from the target dataset. We also show how, in most cases, ADDoG and MADDoG can be used to improve upon baseline state-of-the-art methods when target dataset labels are added and in-the-wild data are considered. Even though our experiments focus on cross-corpus speech emotion, these methods could be used to remove unwanted factors of variation in other settings.
Biqiao (Didi) Zhang, Emily Mower Provost, and Georg Essl. “Cross-corpus Acoustic Emotion Recognition with Multi-task Learning: Seeking Common Ground while Preserving Differences,” IEEE Transactions on Affective Computing, vol: To appear, 2017.
Abstract: There is growing interest in emotion recognition due to its potential in many applications. However, a pervasive challenge is the presence of data variability caused by factors such as differences across corpora, speaker’s gender, and the “domain” of expression (e.g., whether the expression is spoken or sung). Prior work has addressed this challenge by combining data across corpora and/or genders, or by explicitly controlling for these factors. In this work, we investigate the influence of corpus, domain, and gender on the cross-corpus generalizability of emotion recognition systems. We use a multi-task learning approach, where we define the tasks according to these factors. We find that incorporating variability caused by corpus, domain, and gender through multi-task learning outperforms approaches that treat the tasks as either identical or independent. Domain is a larger differentiating factor than gender for multi-domain data. When considering only the speech domain, gender and corpus are similarly influential. Defining tasks by gender is more beneficial than by either corpus or corpus and gender for valence, while the opposite holds for activation. On average, cross- corpus performance increases with the number of training corpora. The results demonstrate that effective cross-corpus modeling requires that we understand how emotion expression patterns change as a function of non-emotional factors.
Privacy in Emotion Recognition
An emotion recognition algorithm that isn’t secure has dire consequences for its users. The consequences range from risks of demographic information being sensed and recorded without a user’s consent to biases that result from a model’s unequal performance across demographic groups. An emerging line of our work focuses on how to design classifiers to mask demographic information and to increase model generalizability across different groups of users.
- Privacy
When we express our emotion, that’s not all we are doing. We are also expressing information about many aspects of our identity. The challenge is that when recognizing emotion, our classifiers are then able to pick up on information that extends beyond the emotion itself. This presents problems as it potentially allows entities performing emotion recognition, with a user’s consent, to recognize other aspects of that user’s identity (e.g., gender) when a user did not consent to allow us. In our recent work, we have quantified this effect and demonstrated how we could use adversarial techniques to mitigate the leakage of demographic data [AAAI 2020].
Mimansa Jaiswal and Emily Mower Provost, “Privacy Enhanced Multimodal Neural Representations for Emotion Recognition,” AAAI. New York, New York. February 2020.
Abstract: Many mobile applications and virtual conversational agents now aim to recognize and adapt to emotions. To enable this, data are transmitted from users’ devices and stored on central servers. Yet, these data contain sensitive information that could be used by mobile applications without user’s consent or, maliciously, by an eavesdropping adversary. In this work, we show how multimodal representations trained for a primary task, here emotion recognition, can unintentionally leak demographic information, which could override a selected opt-out option by the user. We analyze how this leakage differs in representations obtained from textual, acoustic, and multimodal data. We use an adversarial learning paradigm to unlearn the private information present in a representation and investigate the effect of varying the strength of the adversarial component on the primary task and on the privacy metric, defined here as the inability of an attacker to predict specific demographic information. We evaluate this paradigm on multiple datasets and show that we can improve the privacy metric while not significantly impacting the performance on the primary task. To the best of our knowledge, this is the first work to analyze how the privacy metric differs across modalities and how multiple privacy concerns can be tackled while still maintaining performance on emotion recognition.
Time in Emotion Recognition
Emotion data are labeled either statically or dynamically. When emotion is labeled statically, a single sentence (or unit of speech) is assigned a label that is believed to capture the entirity of that sample. The goal of the classifier is then to predict that single label. When emotion is labeled dynamically, a human evaluator (or annotator) is asked to continuously adjust their rating of the emotion present. This provides a time-continuous description of emotion. Classifiers are then trained to predict these dynamic ratings. However, different annotators have very different behavior when it comes to evaluating a given emotional display. These differences must be considered the evaluations from multiple annotators are used.
- Temporal Modeling Papers
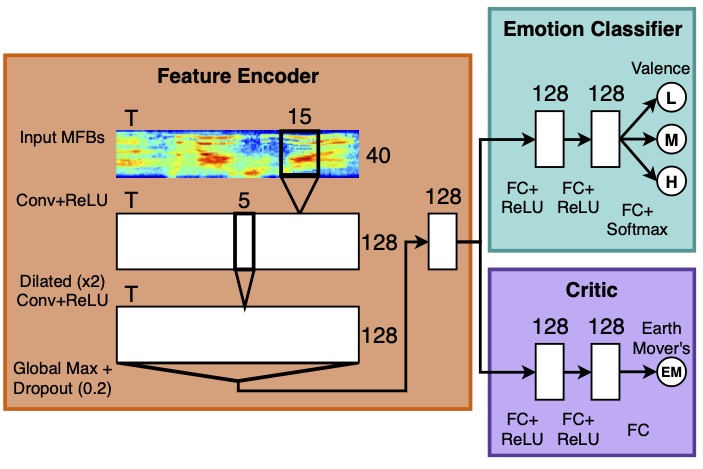
Emotion expression and perception have a natural time course. Human annotation is not instantaneous. However, our machine predictions generally do not take this into account. Our research has created new methods to align the time-scale of emotion prediction with that of the underlying human annotation. One of the largest problems in continuous annotation (when annotators are asked to annotate emotional data, continuously in time) is that the human annotations are not well aligned with the actual data. It is common to observe a lag of two-four seconds between the annotations and the emotional variation in the data. We introduced a new convolutional neural network, which we refer to as the multi-delay sinc network, that is able to simultaneously align and predict labels in an end-to-end manner [IEEE Transactions on Affective Computing 2019]. We found that this approach obtains state-of-the-art speech-only results by learning time-varying delays while predicting dimensional descriptors of emotions. We introduced additional architectures that are designed to more closely align the frequency of human annotation and classifier prediction [Interspeech 2017]. In the RECOLA dataset, continuous annotations were sampled at a frequency of 25 Hz. However, we found that more than 95 percent of the power in these trajectories lies in frequency bands that are lower than 1 Hz. We took this as inspiration to create networks that intentionally smoothed the output emotion predictions using a network composed of both downsampling and upsampling components. We found that the network achieved state-of-the-art performance and, critically, generated smooth output trajectories.
Soheil Khorram, Melvin McInnis, Emily Mower Provost. “Jointly Aligning and Predicting Continuous Emotion Annotations,” IEEE Transactions on Affective Computing, Vol: To appear, 2019.
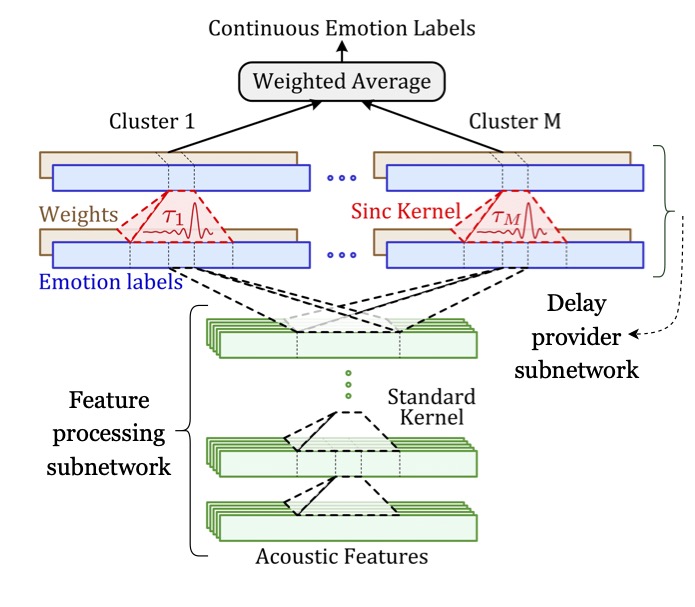
Abstract: Time-continuous dimensional descriptions of emotions (e.g., arousal, valence) allow researchers to characterize short-time changes and to capture long-term trends in emotion expression. However, continuous emotion labels are generally not synchronized with the input speech signal due to delays caused by reaction-time, which is inherent in human evaluations. To deal with this challenge, we introduce a new convolutional neural network (multi-delay sinc network) that is able to simultaneously align and predict labels in an end-to-end manner. The proposed network is a stack of convolutional layers followed by an aligner network that aligns the speech signal and emotion labels. This network is implemented using a new convolutional layer that we introduce, the delayed sinc layer. It is a time-shifted low-pass (sinc) filter that uses a gradient-based algorithm to learn a single delay. Multiple delayed sinc layers can be used to compensate for a non-stationary delay that is a function of the acoustic space. We test the efficacy of this system on two common emotion datasets, RECOLA and SEWA, and show that this approach obtains state-of-the-art speech-only results by learning time-varying delays while predicting dimensional descriptors of emotions.
Soheil Khorram, Melvin McInnis, and Emily Mower Provost. “Trainable Time Warping: aligning time-series in the continuous-time domain.” International Conference on Acoustics, Speech, and Signal Processing (ICASSP). Brighton, England. May 2019.
Abstract: DTW calculates the similarity or alignment between two signals, subject to temporal warping. However, its computational complex- ity grows exponentially with the number of time-series. Although there have been algorithms developed that are linear in the number of time-series, they are generally quadratic in time-series length. The exception is generalized time warping (GTW), which has linear computational cost. Yet, it can only identify simple time warping functions. There is a need for a new fast, high-quality multi-sequence alignment algorithm. We introduce trainable time warping (TTW), whose complexity is linear in both the number and the length of time-series. TTW performs alignment in the continuous-time domain using a sinc convolutional kernel and a gradient-based optimization technique. We compare TTW and GTW on 85 UCR datasets in time-series averaging and classification. TTW outperforms GTW on 67.1% of the datasets for the averaging tasks, and 61.2% of the datasets for the classification tasks.
Soheil Khorram, Zakariah Aldeneh, Dimitrios Dimitriadis, Melvin McInnis, and Emily Mower Provost. “Capturing Long-term Temporal Dependencies with Convolutional Networks for Continuous Emotion.” Interspeech. Stockholm, Sweden, August 2017.
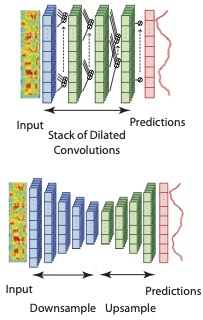
Abstract: The goal of continuous emotion recognition is to assign an emotion value to every frame in a sequence of acoustic features. We show that incorporating long-term temporal dependencies is critical for continuous emotion recognition tasks. To this end, we first investigate architectures that use dilated convolutions. We show that even though such architectures outperform previously reported systems, the output signals produced from such architectures undergo erratic changes between consecutive time steps. This is inconsistent with the slow moving ground-truth emotion labels that are obtained from human annotators. To deal with this problem, we model a downsampled version of the input signal and then generate the output signal through upsampling. Not only does the resulting downsampling/upsampling network achieve good performance, it also generates smooth output trajectories. Our method yields the best known audioonly performance on the RECOLA dataset.
Self-Reported Emotion Recognition
The majority of research in the field of emotion recognition is focused on estimating how a group of outside observers would perceive an emotional display. This is a convenient thing to do, from a machine learning perspective. It allows us to mitigate the challenges that are associated with trying to guess how a given speaker is truly feeling and instead quantify the emotion present in their outward displays of behavior. However, often, particularly in mental health modeling, this isn’t what we need. What we need is to understand how an individual is interpreting their emotion. In this line of work, we investigate the feasibility of self reported emotion recognition and effective methods to estimate these types of labels.
- Self-Reported Emotion Papers
Zhang, Biqiao, and Emily Mower Provost. “Automatic recognition of self-reported and perceived emotions.” Multimodal Behavior Analysis in the Wild. Academic Press, 2019. 443-470.
Abstract: Emotion is an essential component in our interactions with others. It trans- mits information that helps us interpret the meaning behind an individual’s behavior. The goal of automatic emotion recognition is to provide this in- formation, distilling emotion from behavioral data. Yet, emotion may be de- fined in multiple manners: recognition of a person’s true felt sense, how that person believes his/her behavior will be interpreted, or how others actually do interpret that person’s behavior. The selection of a definition fundamen- tally impacts system design, behavior, and performance. The goal of this chapter is to provide an overview of the theories, resources, and ongoing research related to automatic emotion recognition that considers multiple definitions of emotion.
Biqiao Zhang, Georg Essl, and Emily Mower Provost. “Automatic Recognition of Self-Reported and Perceived Emotion: Does Joint Modeling Help?” International Conference on Multimodal Interaction (ICMI). Tokyo, Japan, November 2016.
[Note: full paper, oral presentation, best paper honorable mention]Abstract: Emotion labeling is a central component of automatic emo- tion recognition. Evaluators are asked to estimate the emo- tion label given a set of cues, produced either by them- selves (self-report label ) or others (perceived label). This process is complicated by the mismatch between the inten- tions of the producer and the interpretation of the perceiver. Traditionally, emotion recognition systems use only one of these types of labels when estimating the emotion content of data. In this paper, we explore the impact of jointly modeling both an individual’s self-report and the perceived label of others. We use deep belief networks (DBN) to learn a representative feature space, and model the potentially complementary relationship between intention and percep- tion using multi-task learning. We hypothesize that the use of DBN feature-learning and multi-task learning of self- report and perceived emotion labels will improve the perfor- mance of emotion recognition systems. We test this hypoth- esis on the IEMOCAP dataset, an audio-visual and motion- capture emotion corpus. We show that both DBN feature learning and multi-task learning offer complementary gains. The results demonstrate that the perceived emotion tasks see greatest performance gain for emotionally subtle utter- ances, while the self-report emotion tasks see greatest per- formance gain for emotionally clear utterances. Our results suggest that the combination of knowledge from the self- report and perceived emotion labels lead to more effective emotion recognition systems.
Mental Health Modeling
Our speech, both language and acoustics provides critical insight into an our well-being. In this line of work, we ask how we can design speech-centered approaches to determine level of symptom severity for individuals with bipolar disorder and risk factors for individuals at risk of suicide.
This work is part of a long-running collaboration with Dr. Melvin McInnis at the Prechter Bipolar Research Program (Depression Center, University of Michigan) and Dr. Heather Schatten at Brown University.
- Focus: Individuals with Bipolar Disorder
We discuss our research under the umbrella of PRIORI (Predicting Individual Outcomes for Rapid Intervention). The PRIORI project asks how natural collections of speech can be used to intuit changes in mental health symptom severity. The original version PRIORI was a phone-based app that would record one-side of conversational telephone speech data. This app was used to collect audio data from both individuals with bipolar disorder and individuals at risk for suicide (please see the next section). This collection was the first of its kind.
The project was predicated on the notion that when an individual transitions from a healthy, euthymic state, to a symptomatic depressed or manic state, you can “hear it in their voice.” This framing is very similar to how we generally think about problems such as emotion recognition. However, longitudinal mood expression in daily life is different. In unstructured contexts, an individual isn’t always expressing their mood symptoms. They often have the ability to mask their underlying mood. Consequently, an algorithm that assumes it is possible to consistently map any acoustic information to a mood state is an algorithm that is not likely to succeed. We have found that recognizing mood in natural contexts requires something else. It requires the recognition of symptoms and the modeling of these symptoms over time. Essentially, it requires that our algorithms think about the expression of health in a manner that is similar to how clinicians themselves consider this complex subject. In our PRIORI papers (a subset shown here, but going back to 2014), we have moved towards this goal of recognizing symptoms and evaluating how patterns in these symptoms, primarily emotion, are associated with long-term symptom severity changes.
Minxue (Sandy) Niu, Amrit Romana, Emily Mower Provost. “Capturing Mismatch between Textual and Acoustic Emotion Expressions for Mood Identification in Bipolar Disorder.” Interspeech. Dublin, Ireland. August 2023.
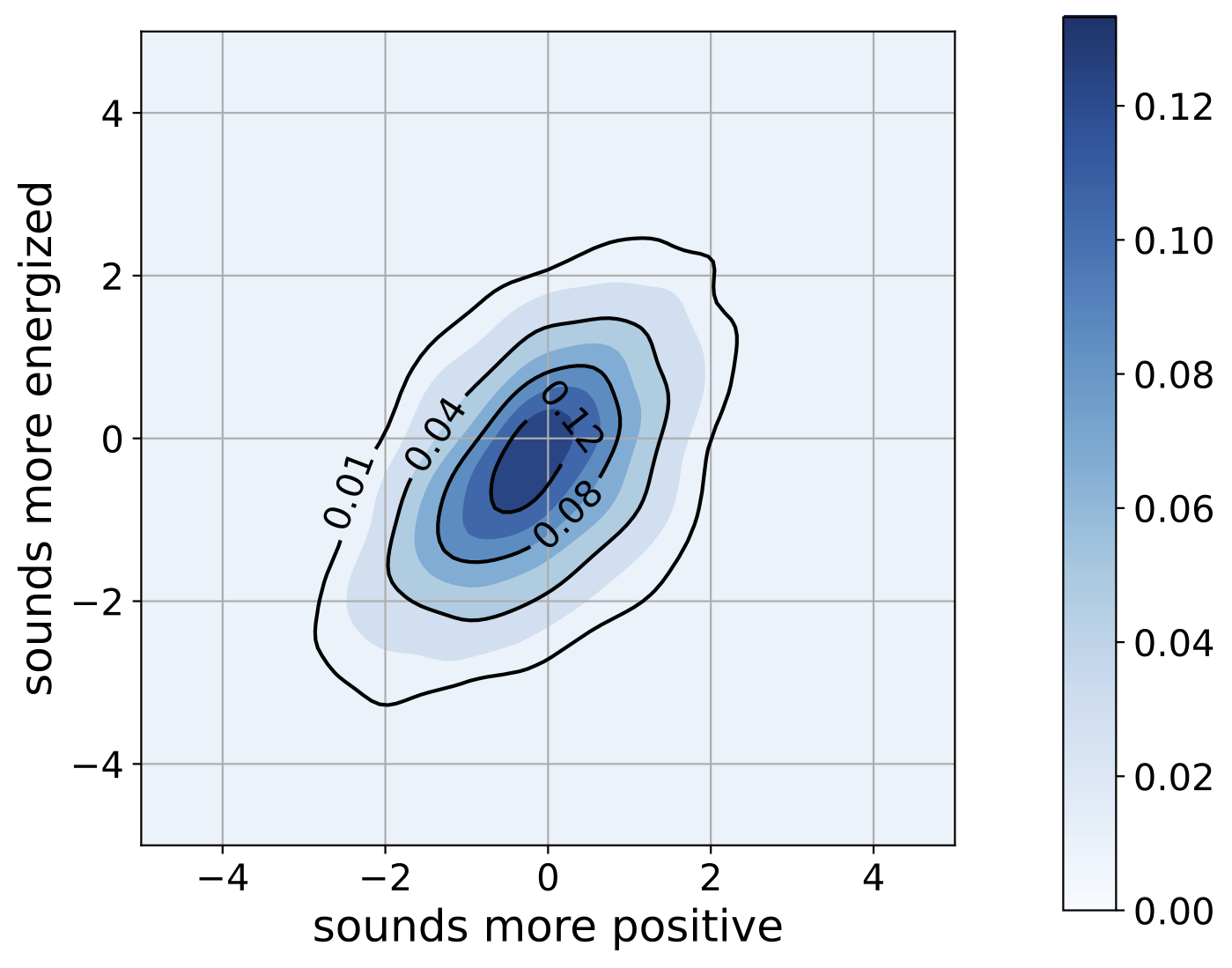
Emotion is a complex behavioral phenomenon, which is expressed and perceived through various modalities, such as language, vocal and facial expressions. Psychiatric research has suggested that the lack of emotional alignment between modalities is a symptom of emotion disorders. In this work, we quantify the mismatch between emotion expressed through language and acoustics, which we refer to as Emotional MisMatch (EMM), as an intermediate step for mood identification. We use a longitudinal dataset collected from people with Bipolar Disorder (BP) and show that symptomatic mood episodes show significantly more EMM, compared to euthymic moods. We propose a fully automatic mood identification pipeline with automatic speech transcription, emotion recognition, and EMM feature extraction. We find that EMM features, although smaller in size, outperform a language-based baseline, and consistently provide improvement when combined with language and/or raw emotion features on mood classification.
Katie Matton, Melvin G McInnis, Emily Mower Provost, “Into the Wild: Transitioning from Recognizing Mood in Clinical Interactions to Personal Conversations for Individuals with Bipolar Disorder.” Interspeech. Graz, Austria. September 2019.
Abstract: Bipolar Disorder, a mood disorder with recurrent mania and depression, requires ongoing monitoring and specialty management. Current monitoring strategies are clinically-based, engaging highly specialized medical professionals who are becoming increasingly scarce. Automatic speech-based monitoring via smartphones has the potential to augment clinical monitoring by providing inexpensive and unobtrusive measurements of a patient’s daily life. The success of such an approach is contingent on the ability to successfully utilize “in-the-wild” data. However, most existing work on automatic mood detection uses datasets collected in clinical or laboratory settings. This study presents experiments in automatically detecting depression severity in individuals with Bipolar Disorder using data derived from clinical interviews and from personal conversations. We find that mood assessment is more accurate using data collected from clinical interactions, in part because of their highly structured nature. We demonstrate that although the features that are most effective in clinical interactions do not extend well to personal conversational data, we can identify alternative features relevant in personal conversational speech to detect mood symptom severity. Our results highlight the challenges unique to working with “in-the-wild” data, providing in- sight into the degree to which the predictive ability of speech features is preserved outside of a clinical interview.
Zakaria Aldeneh, Mimansa Jaiswal, Michael Picheny, Melvin McInnis, Emily Mower Provost. “Identifying Mood Episodes Using Dialogue Features from Clinical Interviews.” Interspeech. Graz, Austria. September 2019.
Abstract: Bipolar disorder, a severe chronic mental illness characterized by pathological mood swings from depression to mania, re- quires ongoing symptom severity tracking to both guide and measure treatments that are critical for maintaining long-term health. Mental health professionals assess symptom severity through semi-structured clinical interviews. During these inter- views, they observe their patients’ spoken behaviors, including both what the patients say and how they say it. In this work, we move beyond acoustic and lexical information, investigating how higher-level interactive patterns also change during mood episodes. We then perform a secondary analysis, asking if these interactive patterns, measured through dialogue features, can be used in conjunction with acoustic features to automatically rec- ognize mood episodes. Our results show that it is beneficial to consider dialogue features when analyzing and building auto- mated systems for predicting and monitoring mood.
Soheil Khorram, Mimansa Jaiswal, John Gideon, Melvin McInnis, Emily Mower Provost. “The PRIORI Emotion Dataset: Linking Mood to Emotion Detected In-the-Wild.” Interspeech. Hyderabad, India. September 2018.
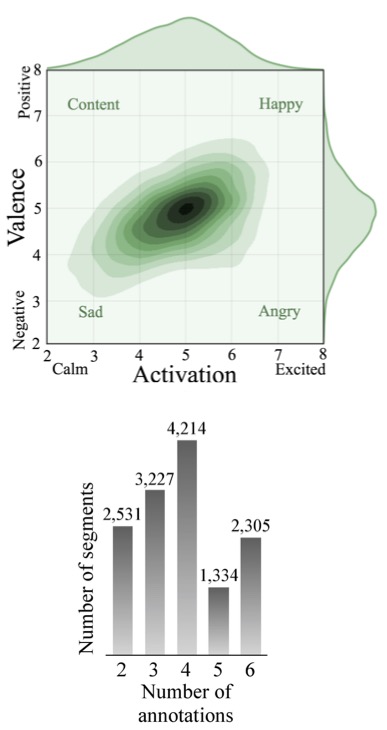
Abstract: Bipolar Disorder is a chronic psychiatric illness characterized by pathological mood swings associated with severe disruptions in emotion regulation. Clinical monitoring of mood is key to the care of these dynamic and incapacitating mood states. Frequent and detailed monitoring improves clinical sensitivity to detect mood state changes, but typically requires costly and limited resources. Speech characteristics change during both depressed and manic states, suggesting automatic methods applied to the speech signal can be effectively used to monitor mood state changes. However, speech is modulated by many factors, which renders mood state prediction challenging. We hypothesize that emotion can be used as an intermediary step to improve mood state prediction. This paper presents critical steps in developing this pipeline, including (1) a new in the wild emotion dataset, the PRIORI Emotion Dataset, collected from everyday smartphone conversational speech recordings, (2) activation/valence emotion recognition baselines on this dataset (PCC of 0.71 and 0.41, respectively), and (3) significant correlation between predicted emotion and mood state for individuals with bipolar disorder. This provides evidence and a working baseline for the use of emotion as a meta-feature for mood state monitoring.
Soheil Khorram, John Gideon, Melvin McInnis, and Emily Mower Provost. “Recognition of Depression in Bipolar Disorder: Leveraging Cohort and Person-Specific Knowledge.” Interspeech. San Francisco, CA, September 2016.
Abstract: Individuals with bipolar disorder typically exhibit changes in the acoustics of their speech. Mobile health systems seek to model these changes to automatically detect and correctly identify current states in an individual and to ultimately predict impending mood episodes. We have developed a program, PRIORI (Predicting Individual Outcomes for Rapid Intervention), that analyzes acoustics of speech as predictors of mood states from mobile smartphone data. Mood prediction systems generally assume that the symptomatology of an individual can be modeled using patterns common in a cohort population due to limitations in the size of available datasets. However, individuals are unique. This paper explores person-level systems that can be developed from the current PRIORI database of an extensive and longitudinal collection composed of two subsets: a smaller labeled portion and a larger unlabeled portion. The person-level system employs the unlabeled portion to extract i-vectors, which characterize single individuals. The labeled portion is then used to train person-level and population-level supervised classifiers, operating on the i-vectors and on speech rhythm statistics, respectively. The unification of these two ap- proaches results in a significant improvement over the baseline system, demonstrating the importance of a multi-level approach to capturing depression symptomatology.
John Gideon, Emily Mower Provost, Melvin McInnis. “Mood State Prediction From Speech Of Varying Acoustic Quality For Individuals With Bipolar Disorder.” International Conference on Acoustics, Speech and Signal Processing (ICASSP). Shanghai, China, March 2016.
Abstract: Speech contains patterns that can be altered by the mood of an in- dividual. There is an increasing focus on automated and distributed methods to collect and monitor speech from large groups of patients suffering from mental health disorders. However, as the scope of these collections increases, the variability in the data also increases. This variability is due in part to the range in the quality of the de- vices, which in turn affects the quality of the recorded data, neg- atively impacting the accuracy of automatic assessment. It is nec- essary to mitigate variability effects in order to expand the impact of these technologies. This paper explores speech collected from phone recordings for analysis of mood in individuals with bipolar disorder. Two different phones with varying amounts of clipping, loudness, and noise are employed. We describe methodologies for use during preprocessing, feature extraction, and data modeling to correct these differences and make the devices more comparable. The results demonstrate that these pipeline modifications result in statistically significantly higher performance, which highlights the potential of distributed mental health systems.
- Focus: Risk of Suicide
Suicide is an increasingly serious public health issue, with the suicide rate increasing from 10.46 to 13.95 deaths per 100,000 between 1999 and 2020, with 45,979 deaths in 2020. A recent meta-analysis suggests that our ability to predict suicide is only slightly above chance levels and has not improved over the past 50 years. Early detection of suicidal ideation is crucial for prevention and intervention. However, relying on self-report of suicide risk is problematic, as the majority of patients deny suicidal ideation and intent in their last communication before their death by suicide. This points to the need for additional, objective monitoring strategies to better know when to intervene.
Emotion dysregulation, defined as the lack of coordination between attentional, cognitive and behavioral responses to emotionally evocative situations when pursuing personally relevant goals, is a hallmark of many conditions, including risk of suicidality, post-traumatic stress disorder (PTSD), depression, bipolar disorder, among others. As such, it is critical that caregivers, clinicians, and individuals themselves are aware of changing levels of emotional dysregulation. Currently, this is possible only through active participation. One common approach is through self-report, in which individuals describe their emotional experiences longitudinally, multiple times per day, which can be quite expensive both in terms of cost and participant burden. These challenges fundamentally limit our ability to understand long-term interactions between emotion and health.
Our recent work has taken strides to accomplish this goal [Interspeech 2019]. We found that we could automatically predict self-reported emotions in a longitudinal corpus of speech collected from individuals at risk for suicide (note: following the PRIORI collection protocol, please see the prior section). We found that the patterns in the variation of emotion were different between those at risk for suicidal ideation and healthy controls. Further, we found that we could use these patterns to predict group membership.
In our recent work, we have asked how we can identify acoustic cues that differentiate those that recently experienced suicidal ideation [Speech Communication 2021]. We used a read speech dataset (a dataset composed of individuals reading). We found that the with recent suicidal ideation had significantly poorer voice quality composite ratings, compared to those in the healthy control group.
Brian Stasak, Julien Epps, Heather T. Schatten, Ivan W. Miller, Emily Mower Provost, and Michael F. Armey. “Read Speech Voice Quality and Disfluency in Individuals with Recent Suicidal Ideation or Suicide Attempt,” Speech Communication, vol:132, pages 10-20. 2021.
Abstract: Individuals that have incurred trauma due to a suicide attempt often acquire residual health complications, such as cognitive, mood, and speech-language disorders. Due to limited access to suicidal speech audio corpora, behavioral differences in patients with a history of suicidal ideation and/or behavior have not been thoroughly examined using subjective voice quality and manual disfluency measures. In this study, we examine the Butler-Brown Read Speech (BBRS) database that includes 20 healthy controls with no history of suicidal ideation or behavior (HC group) and 226 psychiatric inpatients with recent suicidal ideation (SI group) or a recent suicide attempt (SA group). During read aloud sentence tasks, SI and SA groups reveal poorer average subjective voice quality composite ratings when compared with individuals in the HC group. In particular, the SI and SA groups exhibit average ‘grade’ and ‘roughness’ voice quality scores four to six times higher than those of the HC group. We demonstrate that manually annotated voice quality measures, converted into a low-dimensional feature vector, help to identify individuals with recent suicidal ideation and behavior from a healthy population, generating an automatic classification accuracy of up to 73%. Furthermore, our novel investigation of manual speech disfluencies (e.g., manually detected hesitations, word/phrase repeats, malapropisms, speech errors, non-self-correction) shows that inpatients in the SI and SA groups produce on average approximately twice as many hesitations and four times as many speech errors when compared with individuals in the HC group. We demonstrate automatic classification of inpatients with a suicide history from individuals with no suicide history with up to 80% accuracy using manually annotated speech disfluency features. Knowledge regarding voice quality and speech disfluency behaviors in individuals with a suicide history presented herein will lead to a better understanding of this complex phenomenon and thus contribute to the future development of new automatic speech-based suicide-risk identification systems.
John Gideon, Heather T Schatten, Melvin G McInnis, Emily Mower Provost. “Emotion Recognition from Natural Phone Conversations in Individuals With and Without Recent Suicidal Ideation.” Interspeech. Graz, Austria. September 2019.
Abstract: Suicide is a serious public health concern in the U.S., taking the lives of over 47,000 people in 2017. Early detection of suicidal ideation is key to prevention. One promising approach to symptom monitoring is suicidal speech prediction, as speech can be passively collected and may indicate changes in risk. However, directly identifying suicidal speech is difficult, as characteristics of speech can vary rapidly compared with suicidal thoughts. Suicidal ideation is also associated with emotion dysregulation. Therefore, in this work, we focus on the detection of emotion from speech and its relation to suicide. We introduce the Ecological Measurement of Affect, Speech, and Suicide (EMASS) dataset, which contains phone call recordings of individuals recently discharged from the hospital following admission for sui- cidal ideation or behavior, along with controls. Participants self-report their emotion periodically throughout the study. How- ever, the dataset is relatively small and has uncertain labels. Be- cause of this, we find that most features traditionally used for emotion classification fail. We demonstrate how outside emo- tion datasets can be used to generate more relevant features, making this analysis possible. Finally, we use emotion predictions to differentiate healthy controls from those with suicidal ideation, providing evidence for suicidal speech detection using emotion.
Assistive Technology
An individual’s speech patterns provides insight into their physical health. Speech changes are reflective of language impairments, muscular changes, and cognitive impairment. In this line of work, we ask how new speech-centered algorithms can be designed to detect changes in health.
- Focus: Huntington Disease and Parkinson’s disease
Our work on Huntington and Parkinson’s Diseases ask how we can create speech-centered approaches to measure cognitive and motor symptom changes resulting from these neurodegenerative diseases. Huntington Disease (HD) is a progressive disorder which often manifests in motor impairment. Parkinson’s disease (PD) is a central nervous system disorder that causes motor impairment. Recent studies have found that people with PD also often suffer from cognitive impairment (CI). However, when we create speech-centered solutions, solutions trained to predict a gestalt symptom severity score, we often avoid a central question: do our methods capture the motor changes or the cognitive changes? Our recent work in PD has focused on automated transcription and error and disfluency detection, capable of predicting CI in people with PD. This will enable efficient analyses of how cognition modulates speech for people with PD, leading to scalable speech assessments of CI. Our recent work in HD has focused on a central disease characteristic: irregular articulation. We have designed automated pipelines to capture vocal tract movement and articulatory coordination [Interspeech 2020]. We demonstrated that Vocal Tract Coordination (VTC) features, extracted from read speech, can be used to estimate a motor score [Interspeech 2021].
Amrit Romana, John Bandon, Matthew Perez, Stephanie Gutierrez, Richard Richter, Angela Roberts, Emily Mower Provost. “Enabling Off-the-Shelf Disfluency Detection and Categorization for Pathological Speech.” Interspeech. Incheon, Korea. September 2022.
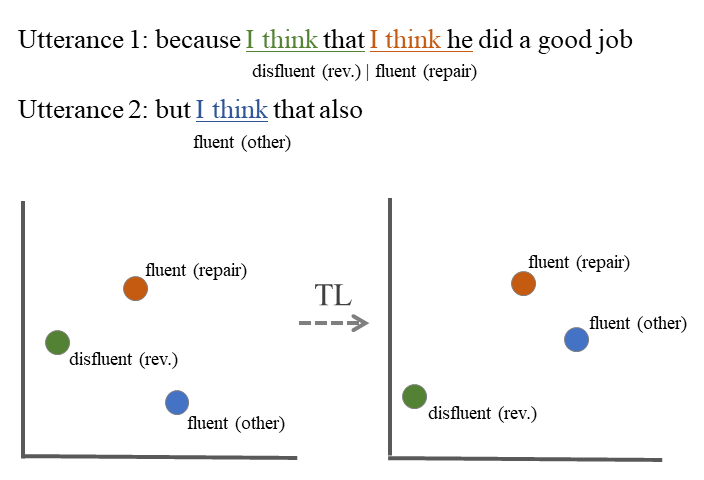
Abstract: A speech disfluency, such as a filled pause, repetition, or revision, disrupts the typical flow of speech. Disfluency detection and categorization has grown as a research area, as recent work has shown that these disfluencies may help in assessing health conditions. For example, for individuals with cognitive impairment, changes in disfluencies may be used to detect worsening symptoms. However, work on disfluency modeling has focused heavily on detection and less on categorization. Work that has focused on categorization has suffered with two specific classes: repetitions and revisions. In this paper, we evaluate how BERT compares to other models on disfluency detection and categorization. We also propose adding a second fine-tuning task in which BERT uses triplet loss to distance repetitions and revisions from their repairs. We find that BERT and BERT with triplet loss outperform previous work on disfluency detection and categorization, particularly on repetitions and revisions. In this paper we present the first analysis of how these models can be fine-tuned on widely available disfluency data, and then used in an off-the-shelf manner on small corpora of pathological speech, where ample training data may not be available.
Matthew Perez, Amrit Romana, Angela Roberts, Noelle Carlozzi, Jennifer Ann Miner, Praveen Dayalu and Emily Mower Provost. ”Articulatory Coordination for Speech Motor Tracking in Huntington Disease.” Interspeech. Brno, Czech Republic. August 2021.
Abstract: Huntington Disease (HD) is a progressive disorder which often manifests in motor impairment. Motor severity (captured via motor score) is a key component in assessing overall HD severity. However, motor score evaluation involves in-clinic visits with a trained medical professional, which are expensive and not always accessible. Speech analysis provides an attrative avenue for tracking HD severity because speech is easy to collect remotely and provides insight into motor changes. HD speech is typically characterized as having irregular articulation. With this in mind, acoustic features that can capture vocal tract movement and articulatory coordination are particularly promising for characterizing motor symptom progression in HD. In this paper, we present an experiment that uses Vocal Tract Coordination (VTC) features extracted from read speech to estimate a motor score. When using an elastic-net regression model, we find that VTC features significantly outperform other acoustic features across varied-length audio segments, which highlights the effectiveness of these features for both shortand long-form reading tasks. Lastly, we analyze the F-value scores of VTC features to visualize which channels are most related to motor score. This work enables future research efforts to consider VTC features for acoustic analyses which target HD motor symptomatology tracking.
Amrit Romana, John Bandon, Matthew Perez, Stephanie Gutierrez, Richard Richter, Angela Roberts and Emily Mower Provost. ”Automatically Detecting Errors and Disfluencies in Read Speech to Predict Cognitive Impairment in People with Parkinson’s Disease.” Interspeech. Brno, Czech Republic. August 2021.
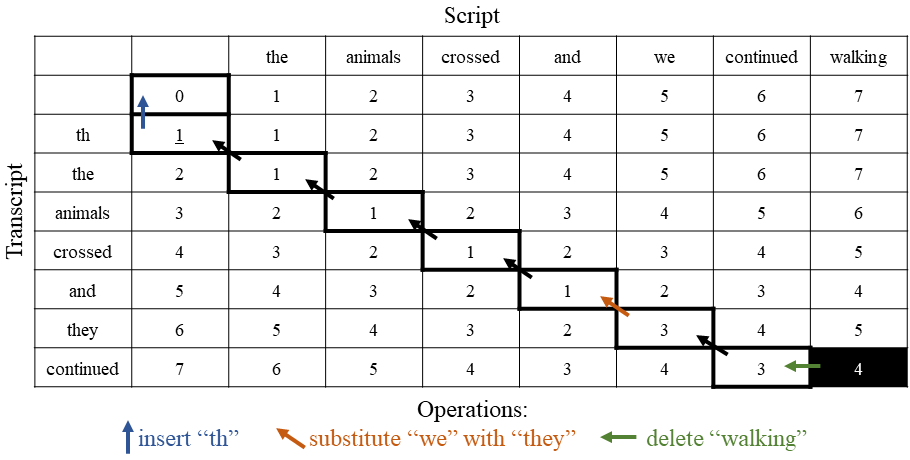
Abstract: Parkinson’s disease (PD) is a central nervous system disorder that causes motor impairment. Recent studies have found that people with PD also often suffer from cognitive impairment (CI). While a large body of work has shown that speech can be used to predict motor symptom severity in people with PD, much less has focused on cognitive symptom severity. Existing work has investigated if acoustic features, derived from speech, can be used to detect CI in people with PD. However, these acoustic features are general and are not targeted toward capturing CI. Speech errors and disfluencies provide additional insight into CI. In this study, we focus on read speech, which offers a controlled template from which we can detect errors and disfluencies, and we analyze how errors and disfluencies vary with CI. The novelty of this work is an automated pipeline, including transcription and error and disfluency detection, capable of predicting CI in people with PD. This will enable efficient analyses of how cognition modulates speech for people with PD, leading to scalable speech assessments of CI.
Amrit Romana, John Bandon, Noelle Carlozzi, Angela Roberts, Emily Mower Provost. “Classification of Manifest Huntington Disease using Vowel Distortion Measures.” Interspeech. Shanghai, China. October 2020.
Abstract: Huntington disease (HD) is a fatal autosomal dominant neurocognitive disorder that causes cognitive disturbances, neuropsychiatric symptoms, and impaired motor abilities (e.g., gait, speech, voice). Due to its progressive nature, HD treatment requires ongoing clinical monitoring of symptoms. Individuals with the gene mutation which causes HD may exhibit a range of speech symptoms as they progress from premanifest to manifest HD. Differentiating between premanifest and manifest HD is an important yet understudied problem, as this distinction marks the need for increased treatment. Speech-based passive monitoring has the potential to augment clinical assessments by continuously tracking manifestation symptoms. In this work we present the first demonstration of how changes in connected speech can be measured to differentiate between premanifest and manifest HD. To do so, we focus on a key speech symptom of HD: vowel distortion. We introduce a set of vowel features which we extract from connected speech. We show that our vowel features can differentiate between premanifest and manifest HD with 87% accuracy.
Matthew Perez, Wenyu Jin, Duc Le, Noelle Carlozzi, Praveen Dayalu, Angela Roberts, Emily Mower Provost. “Classification of Huntington’s Disease Using Acoustic and Lexical Features.” Interspeech. Hyderabad, India. September 2018.
Abstract: Speech is a critical biomarker for Huntington Disease (HD), with changes in speech increasing in severity as the disease progresses. Speech analyses are currently conducted using either transcriptions created manually by trained professionals or using global rating scales. Manual transcription is both expensive and time-consuming and global rating scales may lack sufficient sensitivity and fidelity. Ultimately, what is needed is an unobtrusive measure that can cheaply and continuously track disease progression. We present first steps towards the development of such a system, demonstrating the ability to automatically differentiate between healthy controls and individuals with HD using speech cues. The results provide evidence that objective analyses can be used to support clinical diagnoses, moving towards the tracking of symptomatology outside of laboratory and clinical environments.
- Focus: Aphasia
Our work in aphasia, an expressive/receptive language loss that commonly co-occurs with a stroke, seeks to approximate clinical judgment, focusing on: (1) the development of automatic speech recognition (ASR) systems that are robust to the speech-language errors associated with aphasia and (2) the use of these ASR systems to extract features that are robust to speech errors and are generalizable across individuals to estimate symptom severity and speech intelligibility. We accomplish this goal using deep learning systems augmented with task-specific language models, new alignment algorithms, and symptom-focused feature extraction. Our work has demonstrated that aphasic speech can be automatically transcribed accurately [Interspeech 2020] and that these transcripts can be used to in the feature extraction and classification pipeline [Le 2018].
Matthew Perez, Zakaria Aldeneh, Emily Mower Provost. “Aphasic Speech Recognition using a Mixture of Speech Intelligibility Experts.” Interspeech. Shanghai, China. October 2020.
Abstract: Robust speech recognition is a key prerequisite for semantic feature extraction in automatic aphasic speech analysis. However, standard one-size-fits-all automatic speech recognition models perform poorly when applied to aphasic speech. One reason for this is the wide range of speech intelligibility due to different levels of severity (i.e., higher severity lends itself to less intelligible speech). To address this, we propose a novel acoustic model based on a mixture of experts (MoE), which handles the varying intelligibility stages present in aphasic speech by explicitly defining severity-based experts. At test time, the contribution of each expert is decided by estimating speech intelligibility with a speech intelligibility detector (SID). We show that our proposed approach significantly reduces phone error rates across all severity stages in aphasic speech compared to a baseline approach that does not incorporate severity information into the modeling process.
Duc Le, Keli Licata, and Emily Mower Provost. “Automatic Quantitative Analysis of Spontaneous Aphasic Speech,” Speech Communication, vol: To appear, 2018.
Abstract: Spontaneous speech analysis plays an important role in the study and treatment of aphasia, but can be difficult to perform manually due to the time consuming nature of speech transcription and coding. Techniques in automatic speech recognition and assessment can potentially alleviate this problem by allowing clinicians to quickly process large amount of speech data. However, automatic analysis of spontaneous aphasic speech has been relatively under-explored in the engineering literature, partly due to the limited amount of available data and difficulties associated with aphasic speech processing. In this work, we perform one of the first large-scale quantitative analysis of spontaneous aphasic speech based on automatic speech recognition (ASR) output. We describe our acoustic modeling method that sets a new recognition benchmark on AphasiaBank, a large-scale aphasic speech corpus. We propose a set of clinically-relevant quantitative measures that are shown to be highly robust to automatic transcription errors. Finally, we demonstrate that these measures can be used to accurately predict the revised Western Aphasia Battery (WAB-R) Aphasia Quotient (AQ) without the need for manual transcripts. The results and techniques presented in our work will help advance the state-of-the-art in aphasic speech processing and make ASR-based technology for aphasia treatment more feasible in real-world clinical applications.
Duc Le, Keli Licata, Carol Persad, and Emily Mower Provost. “Automatic Assessment of Speech Intelligibility for Individuals with Aphasia,” IEEE Transactions on Audio, Speech, and Language Processing, vol: 24, no: 11, Nov. 2016.
Abstract: Traditional in-person therapy may be difficult to access for individuals with aphasia due to the shortage of speech-language pathologists and high treatment cost. Computerized exercises offer a promising low-cost and constantly accessible supplement to in-person therapy. Unfortunately, the lack of feedback for verbal expression in existing programs hinders the applicability and effectiveness of this form of treatment. A prerequisite for producing meaningful feedback is speech intelligibility assessment. In this work, we investigate the feasibility of an automated system to assess three aspects of aphasic speech intelligibility: clarity, fluidity, and prosody. We introduce our aphasic speech corpus, which contains speech-based interaction between individuals with aphasia and a tablet-based application designed for therapeutic purposes. We present our method for eliciting reliable ground-truth labels for speech intelligibility based on the perceptual judgment of nonexpert human evaluators. We describe and analyze our feature set engineered for capturing pronunciation, rhythm, and intonation. We investigate the classification performance of our system under two conditions, one using human-labeled transcripts to drive feature extraction, and another using transcripts generated automatically. We show that some aspects of aphasic speech intelligibility can be estimated at human-level performance. Our results demonstrate the potential for the computerized treatment of aphasia and lay the groundwork for bridging the gap between human and automatic intelligibility assessment.
Duc Le, Keli Licata, and Emily Mower Provost. “Automatic Paraphasia Detection from Aphasic Speech: A Preliminary Study.” Interspeech. Stockholm, Sweden, August 2017.
Abstract: Aphasia is an acquired language disorder resulting from brain damage that can cause significant communication difficulties. Aphasic speech is often characterized by errors known as paraphasias, the analysis of which can be used to determine an appropriate course of treatment and to track an individual’s recovery progress. Being able to detect paraphasias automatically has many potential clinical benefits; however, this problem has not previously been investigated in the literature. In this paper, we perform the first study on detecting phonemic and neologistic paraphasias from scripted speech samples in AphasiaBank. We propose a speech recognition system with task-specific language models to transcribe aphasic speech automatically. We investigate features based on speech duration, Goodness of Pronunciation, phone edit distance, and Dynamic Time Warping on phoneme posteriorgrams. Our results demonstrate the feasibility of automatic paraphasia detection and outline the path toward enabling this system in real-world clinical applications.
Duc Le and Emily Mower Provost. “Improving Automatic Recognition of Aphasic Speech with AphasiaBank.” Interspeech. San Francisco, CA, September 2016.
Abstract: Aphasia is an acquired language disorder resulting from brain damage that can cause significant communication difficulties. Aphasic speech is often characterized by errors known as paraphasias, the analysis of which can be used to determine an appropriate course of treatment and to track an individual’s recovery progress. Being able to detect paraphasias automatically has many potential clinical benefits; however, this problem has not previously been investigated in the literature. In this paper, we perform the first study on detecting phonemic and neologistic paraphasias from scripted speech samples in AphasiaBank. We propose a speech recognition system with task-specific language models to transcribe aphasic speech automatically. We investigate features based on speech duration, Goodness of Pronunciation, phone edit distance, and Dynamic Time Warping on phoneme posteriorgrams. Our results demonstrate the feasibility of automatic paraphasia detection and outline the path toward enabling this system in real-world clinical applications.